Reliable multipart resource deletion in a distributed and fragmented system
How to ensure safe deletion of multipart resources (assets) in a system where everything can and will eventually go wrong
The situation
We have some resources whose data is stored into different locations, each part is owned by a different service. Moreover assets can depend on each other, making an asset unusable or broken if its dependency goes missing.
Let’s take the example of a mesh. It has 3 representations: a node in a graph database, a description in a document database and a payload in a blob storage. The main part is the node, it is the piece that
In our representation, a mesh cannot depend on anything else.
The problem
Deleting a mesh means:
Making sure no other asset is dependent on it
Delete the node from the graph database (dependency service)
Delete the description from the document database (asset service)
Delete the payload from the blob storage (asset service)
Potentially deleting everything can take a long time so we need this to happen asynchronously but we need to respond to the client making the request as fast as we can.
If anything unexpected happens in the process, the system should be reliable and make sure that every deletion is always brought to completion even in the case of failure.
Let’s simplify the issue and pretend that an asset can always be deleted, a first naive approach would look something like this.
function delete_asset(const assetUUID) {
delete_asset_node_from_graph_database(assetUUID);
// POINT OF FAILURE
delete_asset_description_from_document_database(assetUUID);
// POINT OF FAILURE
delete_asset_payload_from_blob_storage(assetUUID);
return SUCCESS;
}
In the above pseudo code, every action happens sequentially. If the first call fails, there’s no harm done, the whole operation fails and the client is notified and can try again later.
Where things get spicier is if the first call succeeds and the process fails before getting the chance to proceed to the second call.
We find ourselves in an incoherent situation and a corrupted state where parts of the asset are deleted and other parts are dangling.
The same scenario could happen if the failure happens after the second call but before the third.
One simple solution is to have a some sort of “Garbage Collector” that goes over all the asset data parts and determines whether or not the asset part is dangling. This means going through all asset nodes in the graph database and checking if they have a matching description in the document database and if applicable a matching payload in the blob storage. Then do the same for every description and finally for every payload. Even if this solution is guaranteed to find all corrupted data, it is very computationally heavy and scales linearly with the amount of data we accumulate. This is actually a good last resort solution but should be reserved for real last resort situations.
The solution
Our approach was to mix a synchronous and asynchronous approach. Introducing events into the equation allows us to respond extremely quickly to the request by only processing the critical part of it, i.e. removing the node representing the asset in the graph database. Then an command is sent into the event bus to continue the deletion of the remaining parts. Note that we rely on the fact that a DELETE operation is idempotent, meaning that calling multiple times the operation will always leave the application in the same state.
function delete_asset(const assetUUID) {
delete_asset_node_from_graph_database(assetUUID);
// POINT OF FAILURE
send_event(deleteAssetCommand{assetUUID});
return SUCCESS;
}
function on_delete_asset_command(deleteAssetCommand) {
delete_asset_description_from_document_database(deleteAssetCommand.assetUUID);
// POINT OF FAILURE?
delete_asset_payload_from_blob_storage(deleteAssetCommand.assetUUID);
// POINT OF FAILURE?
deleteAssetCommand.consume();
}
This is a good step forward, but we still have some potential points of failure left. The first one is right after we deleted the node from the graph database and right before we are able to send the command on the event bus. This cannot be easily solved in a step fashion, meaning the state of the request needs to be updated atomically with the request itself. The solution here is to write into the graph database a reminder that this particular delete command has actually been fulfilled at the exact same time we are fulfilling it, i.e. a flag that marks the assets as being deleted from the database.
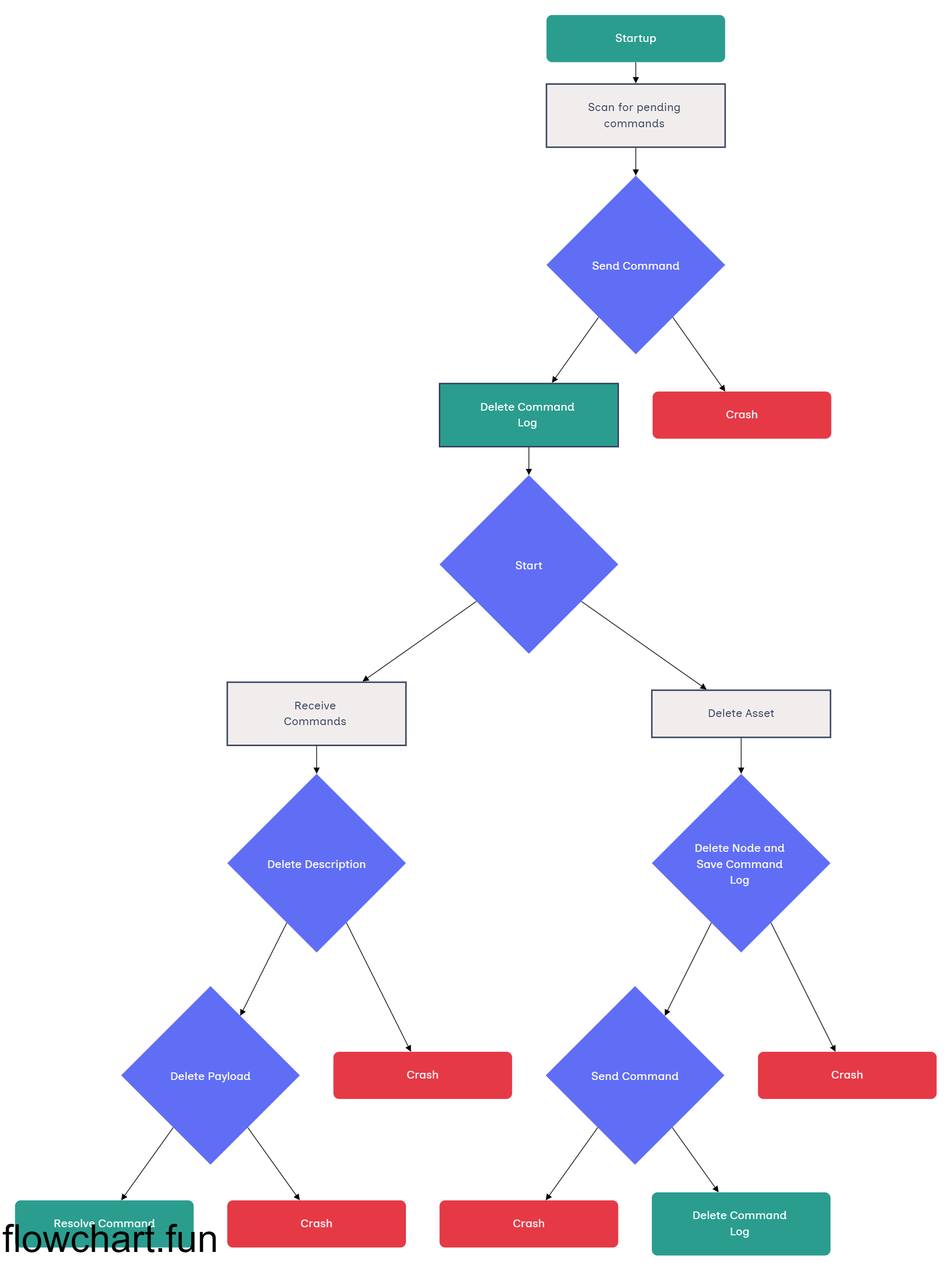
At process startup time we scan the database for those elements and if they exist we gather the data they refer to and we send the event back. The idea here is to have this flow:
Mark the nodes as deleted and create the command flag linked to the deleted assets
Make sure the command is properly sent on the event bus
Remove the command flag from the node database
Receive the command
Delete the rest of the data
Consume the command
Case where the event is not sent:
Mark the nodes as deleted and create the command flag linked to the deleted assets
The process fails and the command is never sent
The process restarts
The process scans the graph database for unsent commands, finds the command, gathers the data and sends it
Receive the command
Delete the description from the document database
Delete the payload from the blob storage
Consume the command
Case where the rest of the data is not deleted:
Mark the nodes as deleted and create the command flag linked to the deleted assets
Make sure the command is properly sent on the event bus
Remove the command flag from the node database
Receive the command
Delete the description from the document database
The process fails
The process restarts
The process scans the graph database for unsent commands, doesn’t find anything and proceeds to its normal state
Receive the command (as it hasn’t been consumed before the failure)
Tries to delete the description from the document database, but as it has already been deleted it doesn’t do anything
Delete the payload from the blob storage
Consume the command
Startup
Scan for pending commands
Send Command
Crash .color_red
Delete Command Log .color_green
Start
Receive Commands
Delete Description
Crash .color_red
Delete Payload
Crash .color_red
Resolve Command .color_green
Delete Asset
Delete Node and Save Command Log
Crash .color_red
Send Command
Crash .color_red
Delete Command Log .color_green